

第一印象与上手体验
访问 Spice AI 网站后,我立即注意到其简洁、以开发者为中心的设计。首屏区域承诺“亚秒级查询性能”和“降低高达 80% 的湖仓成本”,这设定了很高的标准。下方是一个无需注册即可体验的交互式 30 秒演示,让你测试核心功能——这是一个减少摩擦的巧妙设计。仪表盘并未直接展示,但产品似乎同时包含开源运行时和托管云平台。我很快找到了“免费开始”按钮,它指向云层级的注册流程,而 OSS 版本可以本地或边缘部署。网站包含一本拥有 80 多种指南的 cookbook,因此找到起点似乎很直接。对于面向开发者的平台,文档和演示链接被醒目地放置,这一点我很欣赏。
核心功能与技术深度
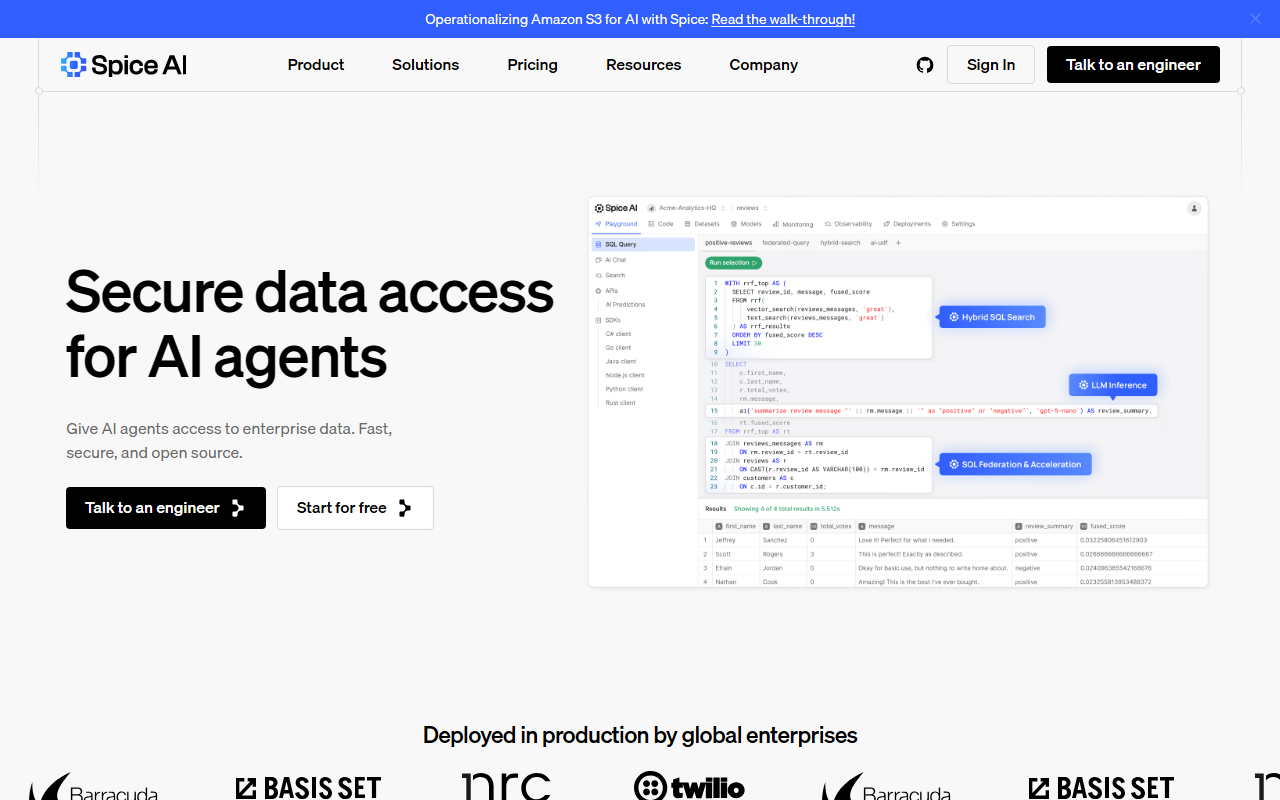
Spice AI 不仅仅是另一个数据管道工具;它是一个专为 AI 上下文构建的数据平台。其突出能力是 SQL 联邦查询与加速:你可以连接到运营数据库、数据湖和数据仓库,然后将工作集物化到内存或磁盘中,实现毫秒级访问。网站声称查询速度提升高达 100 倍——考虑到内存加速,这是一个雄心勃勃但合理的数字。另一个关键功能是 混合搜索,它使用标准 SQL 结合了关键词搜索、向量搜索和全文搜索。这允许你在单个查询中对结构化过滤器、语义相似性和关键词匹配进行排序,这对于需要基于事实、上下文感知结果的 RAG 流水线和 AI 代理至关重要。
第三个支柱是 嵌入式 AI 推理:你可以通过 SQL UDF 或自然语言直接从查询层调用托管或本地 LLM。这意味着你可以在不离开 Spice 运行时的情况下生成摘要、分类实体或翻译文本。在底层,Spice 利用分布式可观测性,跨 SQL、嵌入、搜索和 LLM 调用进行端到端追踪——这对于调试和测量延迟非常有用。该平台还提供 AI 沙箱和安全性,数据集采用最小权限原则,这解决了一个常见的痛点:企业需要在启用 RAG 工作流的同时保持治理完整性。
从技术角度来看,Spice 似乎使用自己用 Rust 编写的轻量级运行时(从其开源仓库推断),这解释了其低资源占用和可移植性。该平台可以部署在任何地方:本地、边缘或托管云上。除了“免费开始”选项外,网站上没有公开列出定价,这可能意味着是 freemium 模式,并有付费层级用于扩展和支持。这种不透明性可能会让一些评估者感到沮丧,但企业用户可以请求演示或与工程师交谈。
市场定位与替代方案
Spice AI 处于传统数据平台(如 Databricks、Snowflake 或 ClickHouse)被重新用于 AI 工作流的领域,但这些平台通常带有繁重的 ETL 和延迟开销。与专注于湖仓分析和 ML 训练的 Databricks 不同,Spice 更加专注:它优化的是实时 AI 推理和服务,而不是批处理。另一个竞争对手是 MindsDB,它也允许基于 SQL 的机器学习和模型服务,但 Spice 通过深度联邦查询、混合搜索和强大的开源精神脱颖而出。该平台已在 Twilio、Barracuda 和 NRC Health 等知名公司投入生产,这增加了可信度。Twilio 的软件架构师指出,Spice 打开了将关键控制平面数据集移动到运行时路径中服务附近的大门——这是对延迟敏感用例的明确证明。
该产品最适合构建 AI 代理、搜索驱动型应用或需要在不移动数据的情况下查询多种数据源的实时个性化功能的团队。希望获得开源、自托管替代方案以避免供应商锁定的开发者会发现 Spice 很有吸引力。然而,需要具备复杂 ETL 管道或大量 ML 训练的完整数据仓库的组织可能需要补充工具。该平台依赖 SQL 联邦查询,这意味着当你的数据源可以通过 SQL 访问时效果最佳;对于非结构化 blob 或流式事件源,你可能需要额外的中间件。
评价与推荐
Spice AI 是一个真正创新的平台,解决了一个真正的痛点:以最小延迟和最大灵活性将 AI 落地到企业数据中。其优势包括亚秒级查询速度、跨来源的统一 SQL、混合搜索和嵌入式 LLM 调用——全部封装在一个开源、可移植的运行时中。交互式演示和全面的 cookbook 使其易于探索。局限性包括云层级缺乏透明定价以及专注于服务而非批处理。如果你正在构建需要快速访问联邦数据的 AI 应用,Spice 值得认真考虑。我建议从免费层级开始,测试其联邦查询和加速能力。对于已经处于 Databricks 或 Snowflake 生态系统的企业,Spice 可以补充这些栈,而不是取代它们。请访问 Spice AI https://spice.ai/ 自行探索。






评论